sudire
Sufficient dimension reduction (SDR) is a recent take on dimension reduction, where one aims to estimate a set of latent variables
that are linear combinations of the original variables 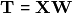 in such a way that the subspace spanned by them contains all information
relevant to the dependent variable in such a way that the subspace spanned by them contains all information relevant to the dependent variable:
in such a way that the subspace spanned by them contains all information
relevant to the dependent variable in such a way that the subspace spanned by them contains all information relevant to the dependent variable:
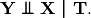 Here,
Here, 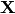 is a sample of
is a sample of 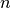 cases of a
cases of a  variate random variable and
variate random variable and  is a sample of the dependent variable,
is a sample of the dependent variable,  is a
is a 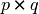 matrix with
matrix with  , and
, and 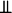 denotes statistical independence.
A lot of research has been done over the last thirty years investigating different approaches in
terms of asymptotics and assumptions made in each of the approaches. A good textbook
providing an overview of approaches to SDR is Li (2018). The subpackage sudire contains
implementations of a broad set of these approaches.
denotes statistical independence.
A lot of research has been done over the last thirty years investigating different approaches in
terms of asymptotics and assumptions made in each of the approaches. A good textbook
providing an overview of approaches to SDR is Li (2018). The subpackage sudire contains
implementations of a broad set of these approaches.
Generally speaking, SDR techniques roughly resort in three categories. At first, there is a successful set of approaches to SDR based on slicing the original space. Examples of these are sliced inverse regression (SIR, Li (1991)) and sliced-average variance estimation (SAVE, Cook (2000)). A second group of developments has involved selective focus on certain directions, which has resulted in, among others, directional regression (DR, Li (2007)), principal Hessian directions (PHD, Li (1992)) and the iterative Hessian transformations (IHT, Cook and Li (2002)).
While all of the aforementioned methods are included in sudire and would merit a broader discussion, at this point we would like to highlight that sudire contains implementations of a more recent approach as well. The latter has, so far, resulted in three methods, all three of which share the following advantages: they do not require conditions of linearity or constant covariance, nor do they need distributional assumptions, yet they may be computationally more demanding. This third group of SDR algorithms estimates a basis of the central subspace as:

where  is an arbitrary
is an arbitrary  matrix,
matrix, ![h \in [1,\min(n,p)]](_images/math/4580aa8c9a9591da82091f453e0f2a5d36009cb8.png) . Here,
. Here, 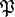 can be any statistic, that estimate a subspace whose complement
is independent of . Currently implemented statistics are :
can be any statistic, that estimate a subspace whose complement
is independent of . Currently implemented statistics are :
distance covariance (Székely, Rizzo, and Bakirov 2007), leading to option dcov-sdr (Sheng and Yin 2016);
martingale difference divergence (Shao and Zhang 2014), leading to option mdd-sdr (Zhang, Liu, Wu, and Fang 2019);
ball covariance (Pan, Wang, Xiao, and Zhu 2019), leading to option bcov-sdr (Zhang and Chen 2019)
Usage
|
SUDIRE Sufficient Dimension Reduction |
Dependencies
From sklearn.base: BaseEstimator,`TransformerMixin`,`RegressorMixin`
From sklearn.utils: _BaseComposition
copy
From scipy.stats : trim_mean
From scipy.linalg: inv, sqrtm
cython
From ipopt : minimize_ipopt
numpy
From statsmodels.regression.linear_model: OLS
statsmodels.robust
References
Wenhui Sheng and Xiangrong Yin Sufficient Dimension Reduction via Distance Covariance, in: Journal of Computational and Graphical Statistics (2016), 25, issue 1, pages 91-104.
Yu Zhang, Jicai Liu, Yuesong Wu and Xiangzhong Fang, A martingale-difference-divergence-based estimation of central mean subspace, in: Statistics and Its Interface (2019), 12, number 3, pages 489-501.
Li K-C, Sliced Inverse Regression for Dimension Reduction, Journal of the American Statistical Association (1991), 86, 316-327.
R.D. Cook, and Sanford Weisberg, Sliced Inverse Regression for Dimension Reduction: Comment, Journal of the American Statistical Association (1991), 86, 328-332.
Li and S.Wang, On directional regression for dimension reduction, Journal of the American Statistical Association (2007), 102:997–1008.
K.-C. Li., On principal hessian directions for data visualization and dimension reduction:Another application of stein’s lemma, Journal of the American Statistical Association(1992)., 87,1025–1039.
Cook and B. Li., Dimension Reduction for Conditional Mean in Regression, The Annals of Statistics(2002)30(2):455–474.
Jia Zhang and Xin Chen, Robust Sufficient Dimension Reduction Via Ball Covariance Computational Statistics and Data Analysis 140 (2019) 144–154
Li B, Sufficient Dimension Reduction: Methods and Applications with R. (2018) Chapman& Hall /CRC, Monographs on Statistics and Applied Probability, New York