ppdire
Beyond discussion, the class of dimension reduction with the longest standing history accessible through direpack, is projection pursuit (PP) dimension reduction.
Let 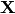 be a data matrix that is a sample of
be a data matrix that is a sample of 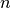 cases of a
cases of a  variate random variable and
variate random variable and 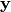 be a sample of a corresponding depending variable, when applicable.
The set of projection pursuit scores
be a sample of a corresponding depending variable, when applicable.
The set of projection pursuit scores 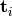 that span the columns of
that span the columns of  are defined as linear combinations of the original variables:
are defined as linear combinations of the original variables: 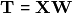 , where the
, where the 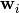 are
the solution to the optimization problem:
are
the solution to the optimization problem:
(1)
where ![i,j \in [1,\min(n,p)]](_images/math/4588dc9f581bc7f3c4ab8f2329f11f23a4553e58.png) ,
, 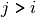 and the set
and the set  if data for a dependent variable
if data for a dependent variable  exist and is a singleton containing otherwise.
Maximization of this criterion is very flexible and the properties of the dimension reduction accomplished according to it can vary widely, mainly dependent on the presence or absence of dependent
variable data, as well as on
exist and is a singleton containing otherwise.
Maximization of this criterion is very flexible and the properties of the dimension reduction accomplished according to it can vary widely, mainly dependent on the presence or absence of dependent
variable data, as well as on 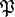 , which in the PP literature is referred to as the projection index.
, which in the PP literature is referred to as the projection index.
dicomo
The projection index determines which method is being calculated. In direpack, projection pursuit can be called through the ppdire subpackge and class object, which allows the user to pass any function of appropriate dimensionality as a projection index. However, a set of popular projection indices deriving from (co-)moments, are provided as well through the dicomo subpackage. For several of these, plugging them in leads to well-established methods. They comprise:
Moment statistics: variance (PCA), higher order moments
Co-moment statistics: covariance (PLS), higher order co-moments
Standardized moments: skewness (ICA), kurtosis (ICA)
Standardized co-moments: correlation coefficient (CCA), co-skewness, co-kurtosis
Linear combinations of (standardized co-) moments. Here, the capi.py file in the ppdire subpackage delivers to co-moment analysis projection index (Serneels2019).
Products of (co-)moments. Particularly the continuum association measure has been provided, which is given by
. Using this continuum measure produces continuum regression (CR, Stone and Brooks (1990)). CR is equivalent to PLS for
and approaches PCA as
.
pp optimizers
Early ideas behind PP was the ability to scan all directions maximizing the projection index as denoted in (1). This essentially corresponds to a brute force optimization technique, which can be computationally very demanding. For instance, both PCA and PLS, can be solved analytically, leading to efficient algorithms that do not directly optimize (1). Whenever the projection index plugged in, leads to a convex optimization problem, it is advisable to apply an efficient numerical optimization technique. For that purpose,ppdire has the option to use scipy.optimize’s sequential least squares quadratic programming optimization (SLSQP). However, for projection indices based on ordering or ranking data, such as medians or trimmed (co-)moments, the problem is no longer convex and cannot be solved through SLSQP. For those purposes, the grid algorithm is included, which was originally developed to compute RCR (Filzmoser, Serneels, Croux, andVan Espen 2006).
Regularized regression
While the main focus of direpack is dimension reduction, all dimension reduction techniques offer a bridge to regularized regression.
This can be achieved by regressing the dependent variable onto the estimated dimension reduced space. The latter provides regularization of the covariance matrix,
due to the constraints in (1), and allow to perform regression for an undersampled . The classical estimate is to predict through least squares regression:
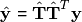
which again leads to well-established methods such as principal component regression (PCR), PLS regression, etc.
Usage
|
PPDIRE Projection Pursuit Dimension Reduction |
|
The dicomo class implements (co)-moment statistics, covering both clasical product-moment statistics, as well as more recently developed energy statistics. |
Dependencies
From sklearn.base: BaseEstimator,`TransformerMixin`,`RegressorMixin`
From sklearn.utils: _BaseComposition
copy
scipy.stats
From scipy.linalg: pinv2
From scipy.optimize: minimize
numpy
From statsmodels.regression.quantile_regression: QuantReg
From sklearn.utils.extmath: svd_flip
References
Peter Filzmoser, Sven Serneels, Christophe Croux and Pierre J. Van Espen, Robust Multivariate Methods: The Projection Pursuit Approach, in: From Data and Information Analysis to Knowledge Engineering,Spiliopoulou, M., Kruse, R., Borgelt, C., Nuernberger, A. and Gaul, W., eds., Springer Verlag, Berlin, Germany, 2006, pages 270–277.
Sven Serneels, Projection pursuit based generalized betas accounting for higher order co-moment effects in financial market analysis, in: JSM Proceedings, Business and Economic Statistics Section. Alexandria, VA: American Statistical Association, 2019, 3009-3035.
Chen, Z. and Li, G., Robust principal components and dispersion matrices via projection pursuit, Research Report, Department of Statistics, Harvard University, 1981.
Peter Filzmoser, Christophe Croux, Pierre J. Van Espen, Robust Continuum Regression, Sven Serneels, Chemometrics and Intelligent Laboratory Systems, 76 (2005), 197-204.
Stone M, Brooks RJ (1990). “Continuum Regression: Cross-Validated Sequentially Constructed Prediction Embracing Ordinary Least Squares, Partial Least Squares and PrincipalComponents Regression.”Journal of the Royal Statistical Society. Series B (Methodological),52, 237–269.